This answer is not useful. Using this approach data is randomly distributed across the partitions rather than grouped.

Datastage Partitioning Youtube
The round robin method always creates approximately equal-sized partitions.

. Hash Partitioning is one of the most popular and frequently used techniques in the Data Stage. Rows distributed based on values in specified keys. If set to true or 1 partitioners will not be added.
Create index index_name rebuild partition partition_name with the fitting values for index_name and partition_nme. This is commonly used to partition on tag fields. The data partitioning techniques are.
Basically there are two methods or types of partitioning in Datastage. One or more keys with different data types are supported. Determines partition based on key-values.
Replicates the DB2 partitioning method of a specific DB2 table. Rows are randomly distributed across partitions. All MA rows go into one partition.
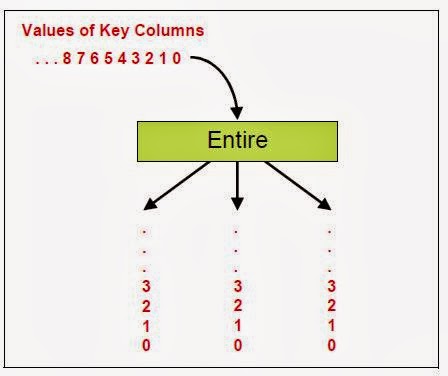
Same Key Column Values are Given to the Same Node. Server jobs were doesnt support the partitioning techniques but parallel jobs support the partition techniques. As lookup is suggested only when the data volume is low compared to the available memory so the use of Entire partitioning is the best partitioning technique to be used for a lookup stage.
Existing Partition is not altered. Types of partition. But I found one better and effective E-learning website related to Datastage just have a look.
Key Based Partitioning Partitioning is based on the key column. All key-based stages by default are associated with Hash as a Key-based Technique. DataStage PX version has the ability to slice the data into chunks and process it simultaneously.
All CA rows go into one partition. Divides a data set into approximately equal-sized partitions each of which contains records with key columns within a specified range. Partition by Key or hash partition - This is a partitioning technique which is used to partition data when the keys are diverse.
The records are partitioned using a modulus function on the key column selected from the Available list. Expression for StgVarCntr1st stg var-- maintain order. So you could try to rebuild the correponding index partition by the use of.
This method is the one normally used when InfoSphere DataStage initially partitions data. This is commonly used to partition on tag fields. Datastage supports a few types of Data partitioning methods which can be implemented in parallel stages.
Hash Partitioning is one of the most popular and frequently used techniques in the Data Stage. DataStage provides the options to Partition the data ie send specific data to a single node or also send records in round robin fashion to the available nodes. If set to false or 0 partitioners may be added depending upon your job design and options chosen.
This method is the one normally used when InfoSphere DataStage initially partitions data. Data Partitioning And Collecting In Datastage Data Warehousing Data Warehousing. Partition techniques in datastage.
Determines partition based on key-values. However we can also use Hash partitioning method for a lookup stage. This method is useful for resizing partitions of an input data set that are not equal in size.
Create index index_name rebuild partition partition_name with the fitting values for index_name and partition_nme. Ie the appropriate partitioning method can be used. In DataStage we need to drag and drop the DataStage objects and also we can convert it to.
In most cases DataStage will use hash partitioning when inserting a partitioner. There are various partitioning techniques available on DataStage and they are. Partition by Key or hash partition - This is a partitioning technique which is used to partition data when the keys are.
The condition for using the has technique is that the has partition should be performed on the. Round robin partition is another partitioning technique to uniformly distribute the data on each of the destination. Datastage is a tool set for designing developing and running applications that populateone or more tables in a data warehouse or data mart.
DataStage provides partitioning and parallel processing techniques which allow the DataStage jobs to process an enormous volume of data quite faster. When InfoSphere DataStage reaches the last processing node in the system it starts over. Rows distributed independently of data values.
Free Apns For Android. This method is similar to hash by field but involves simpler computation. Collecting is the opposite of partitioning and can be defined as a process of bringing back data partitions into a single sequential stream one data partition.
Differentiate Informatica and Datastage. Show activity on this post. APT_NO_PARTITION_INSERTION simply control whether or not partitioners will be added where needed.
Rows are evenly processed among partitions. The message says that the index for the given partition is unusable. Data Partitioning And Collecting In Datastage Data Warehousing Data Warehousing All key-based stages by default are associated with Hash as a Key-based Technique.
Partition techniques in datastage. The records are partitioned randomly based on the output of a random number generator. Using partition parallelism the same job would effectively be run simultaneously by several processors each handling a separate subset of the total data.
The records are hashed into partitions based on the value of a key column or columns selected from the Available list. Key less Partitioning Partitioning is not based on the key column. Collecting is the opposite of partitioning and can be defined as a process of bringing back data partitions into a single sequential stream one data partition.
Agenda Introduction Why do we need partitioning Types of partitioning. This post is about the IBM DataStage Partition methods. The round robin method always creates approximately equal-sized partitions.
Partition by Key or hash partition - This is a partitioning technique which is used to partition data when the keys are diverse. Under this part we send data with the Same Key Colum to the same partition. When InfoSphere DataStage reaches the last processing node in the system it starts over.
The DataStage developer only needs to specify the algorithm to partition the data not the degree of parallelism or where the job will execute. Partition techniques in datastage. Partition by Key or hash partition - This is a partitioning technique which is used to partition.
But this method is used more often for parallel data processing. This method is the one normally used when InfoSphere DataStage initially partitions data. Partition is to divide memory or mass storage into isolated sections.
Rows distributed based on values in specified keys. Introduction Strength of DataStage Parallel Extender is in the parallel processing capability it brings into your data extraction and transformation applications.
Partitioning Technique In Datastage
Dev S Datastage Tutorial Guides Training And Online Help 4 U Unix Etl Database Related Solutions Data Partitioning Collecting Methods Examples

Partitioning Technique In Datastage

Partitioning Technique In Datastage

Datastage Types Of Partition Tekslate Datastage Tutorials

Dev S Datastage Tutorial Guides Training And Online Help 4 U Unix Etl Database Related Solutions Data Partitioning Collecting Methods Examples

Hash Partitioning Datastage Youtube

Datastage Types Of Partition Tekslate Datastage Tutorials
0 comments
Post a Comment